
😱How Chinese Researchers Plan to Build Self-Improving AI
If achieved, this would be the holy grail of AI, the Technological Singularity.

My wife is obsessed with AI lately. She asked me “if I talk to an AI more often, will it get to know me better? Will the model itself get smarter?” I told her the product will become more personalzied based on your previous conversations, but under the hood, today’s AI systems have fixed architecture, model weights after training. Essetnaily the model itself doesn’t change or learn anything new because of your specific inputs.
But what my wife was imagining—a truly self-improving AI—is exactly what the world’s top labs are racing to build next.
Silicon Valley has a new buzzword: Recursive Self-Improvement (RSI). The concept—where an AI model autonomously, repeatedly improves its own intelligence—has become the ultimate goal for top labs racing toward Artificial Super Intelligence (ASI).
The timelines are moving fast. Anthropic has warned that AI models are nearing the capability to improve without human intervention, adding that they are even willing to slow down if risks escalate. OpenAI’s Sam Altman said in a recent blog that by March 2028, a significant portion of their AI research could be conducted by AI working alongside human researchers.
, and Claude Mythos Preview.")
If achieved, this would be the holy grail of AI, the Technological Singularity. Popularized by Ray Kurzweil, this is the hypothetical tipping point where technological growth accelerates beyond human control or comprehension. The modern idea traces back to mathematician I.J. Good in 1965, who hypothesized that once an AI reaches human-level intelligence, it can rapidly redesign its own software and hardware, triggering an “intelligence explosion.”
A bunch of neolabs have emerged to explore this direction. Recursive Intelligence is a new research lab founded by former Salesforce Chief AI Scientist and You.com CEO Richard Socher. The company’s Chief Scientist Tian Yuandong recently explained their mission to Chinese media, which perfectly distills what RSI looks like in practice:
Recursive self-improvement means using AI to optimize certain steps of AI development to make the model stronger, and then continuing to iterate upward on that new foundation. Specifically, we want AI to handle tasks that still require manual human effort today—like scientists searching for new ideas, discovering new logic, or leveraging AI for reinforcement learning during the training process.
Our ultimate vision is to build a system where you plug in computational resources, and it outputs new knowledge, insights, and discoveries. As our website states, our goal is ‘maximizing the knowledge discovery rate’ to accelerate human progress.

Researchers in China are also closely following this trend. Lin Junyang, the former tech lead of Alibaba’s Qwen team, recently shared his thoughts on X.

Lin’s new lab, which has reportedly closed the first financing round at a $2 billion valuation, is rumored to explore this exact direction, alongside world models and embodied AI.
To be clear, today’s RSI isn’t a sci-fi superintelligence autonomously designing its next-gen successor from scratch. It’s still in an early stage like automating critical pieces of the AI research and development pipeline. Automated data generation for example has been for years a typical self-improving technique for models. AlphaZero, the go-playing AI invented by Google Deepmind, improved itself via self-play without relying on human data.
Before ChatGPT went viral, AutoML and Neural Architecture Search (NAS)—using AI to automate the design of neural networks—were incredibly hot topics. NAS eventually lost the spotlight because model architectures converged, and scaling data and compute became more important than micro-optimizing algorithms. However, looking back, NAS was absolutely an early form of self-improvement research.
This time is different, because the foundation models themselves are now incredibly powerful. They possess vast world knowledge, strong reasoning abilities, and most importantly the ability to write code and act in an agentic behavier. In top AI labs, AI is already writing 90% to 95% of the code. Therefore RSI is building on a highly capable foundation where the model itself possesses the tools to potentially modify its own behavior.
Furthermore, as AI agents mature, researchers are also studying self-improving agents. These systems can interact with and learn from their environments, autonomously extracting memories and skills rather than relying on human engineering, and iterating on what they learn.
Self-Improving AI 101
One of the best ways to understand a rapidly emerging AI topic is to look for a systematic survey paper. Luckily, I found a great one, A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Superintelligence. This collaborative paper involves over 10 top global universities—including Princeton and Carnegie Mellon from the U.S., and Tsinghua, Shanghai Jiao Tong, and Fudan University from China—and is predominantly authored by Chinese researchers.
The paper argues that the core problem of today’s LLMs is their parameters are static. They don’t adapt to new tasks, knowledge, or changing environments. As we deploy LLMs in open-ended, interactive environments, this rigidity will become a bottleneck. To solve this, the survey puts self-improvement AI around four foundational questions:
What to evolve? This focuses on modifying the models themselves, the context (like memory and prompts), the tools they use, and their underlying architecture.
When to evolve? Evolution happens in two ways: intra-test-time (real-time adaptation while performing a task) and inter-test-time (learning between tasks by accumulating experience over time).
How to evolve? The authors outline three major paradigms: reward-based evolution, imitation/demonstration learning, and population-based/evolutionary methods.
Where to evolve? This spans general domains like memory mechanisms, model-agent co-evolution, and curriculum-driven training, as well as specialized industries like coding, GUI agents, finance, medicine, and education.
The paper also identifies five key metrics for evaluating self-evolving agents:
Adaptivity: Can the model actually improve its performance?
Retention: Does it remember past knowledge, or does it suffer from catastrophic forgetting?
Generalization: Can it transfer its newly learned skills to entirely new tasks?
Efficiency: At what computational and financial cost does this evolution happen?
Safety: Can it improve without experiencing harmful drift or unintended behavioral alignment issues?
Inside the ICLR 2026 RSI Workshop

When I researched this topic, I found the Recursive Self-Improvement Workshop at ICLR 2026. Self-described as possibly the world’s first workshop dedicated to RSI, it was backed by Tencent and the Beijing Academy of Artificial Intelligence (BAAI).
What caught my attention was four out of 11 committee members are Chinese researchers representing ByteDance, Tencent, CUHK, and BAAI. It made me wonder where exactly China stands in the race for self-improving AI.
The primary organizer and contact for the workshop is Zhuge Mingchen. He earned his computer science PhD at KAUST under the mentorship of Jürgen Schmidhuber—the uncrowned godfather of AI. Zhuge recently moved to Silicon Valley to become a founding member of Recursive Intelligence. Looking back at his 2024 paper MetaGPT, he predicted that multi-agent frameworks would inevitably need continuous self-optimization and ability evolution to scale.
The accepted papers at the workshop point exactly to where the tech is going, from LLM agents training models during post-training, to frameworks that meta-learn memory designs to completely replace human engineering, and fully autonomous setups where multi-agent co-evolution removes the need for external data. Yet, despite the Chinese-heavy committee, there were few research submissions credited to mainland commercial AI labs or corporate giants.
So what are China’s frontier AI labs actually building behind the scenes?
Self-Improving AI Research from Chinese Labs
A recent South China Morning Post story revealed that several major Chinese players are already reporting internal progress.
Xiaomi’s AI lead Luo Fuli predicts fully self-evolving AI could arrive within just 1–2 years. MiniMax claims its M3 model autonomously reproduced an award-winning research paper in 12 hours and optimized complex GPU code in 24 hours. Alibaba said that its Qwen model completed a similar code-optimization task in 35 hours—roughly 10 times faster than human engineering teams. ByteDance and Tsinghua University published research showing a 100% speedup in hardware kernel optimization using AI research agents.
I dug in more academic papers coming out of these labs, which generally fall into three distinct strategies:
Zero Data
Much like AlphaZero mastered Go by playing against itself, Chinese researchers are using AI to generate its own training data from scratch.
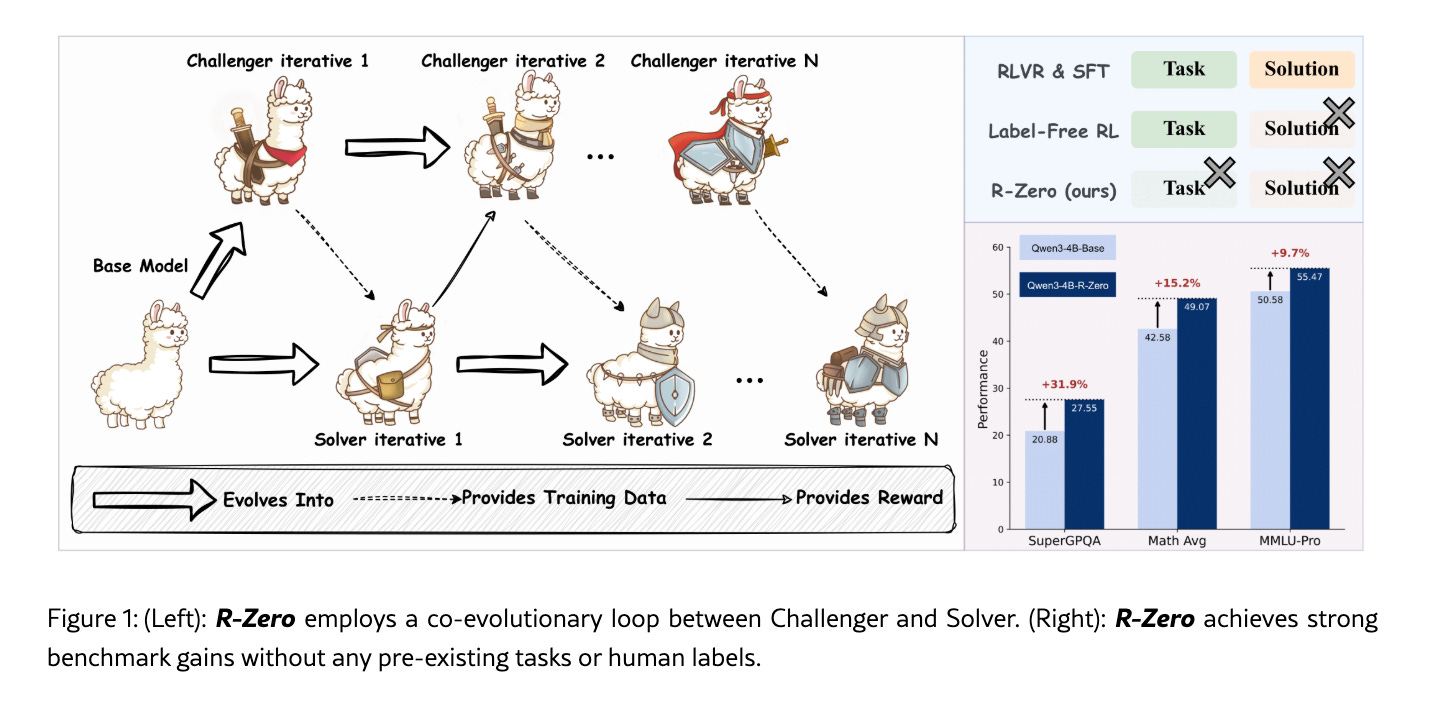
Tencent AI Lab in Seattle introduced R-Zero, a fully autonomous framework that builds training data with zero human input. It pairs a Challenger (designed to generate tasks that push the model to its absolute limits) with a Solver (the model finding the solution). This closed loop substantially improves reasoning capabilities across various backbone LLMs without needing pre-existing labels.
Tsinghua University followed a similar direction with Absolute Zero Reasoner (AZR), except they condensed the loop into a single model playing both Proposer and Solver to generate and solve code-verified tasks.

Automating Policy and Credit Assignment
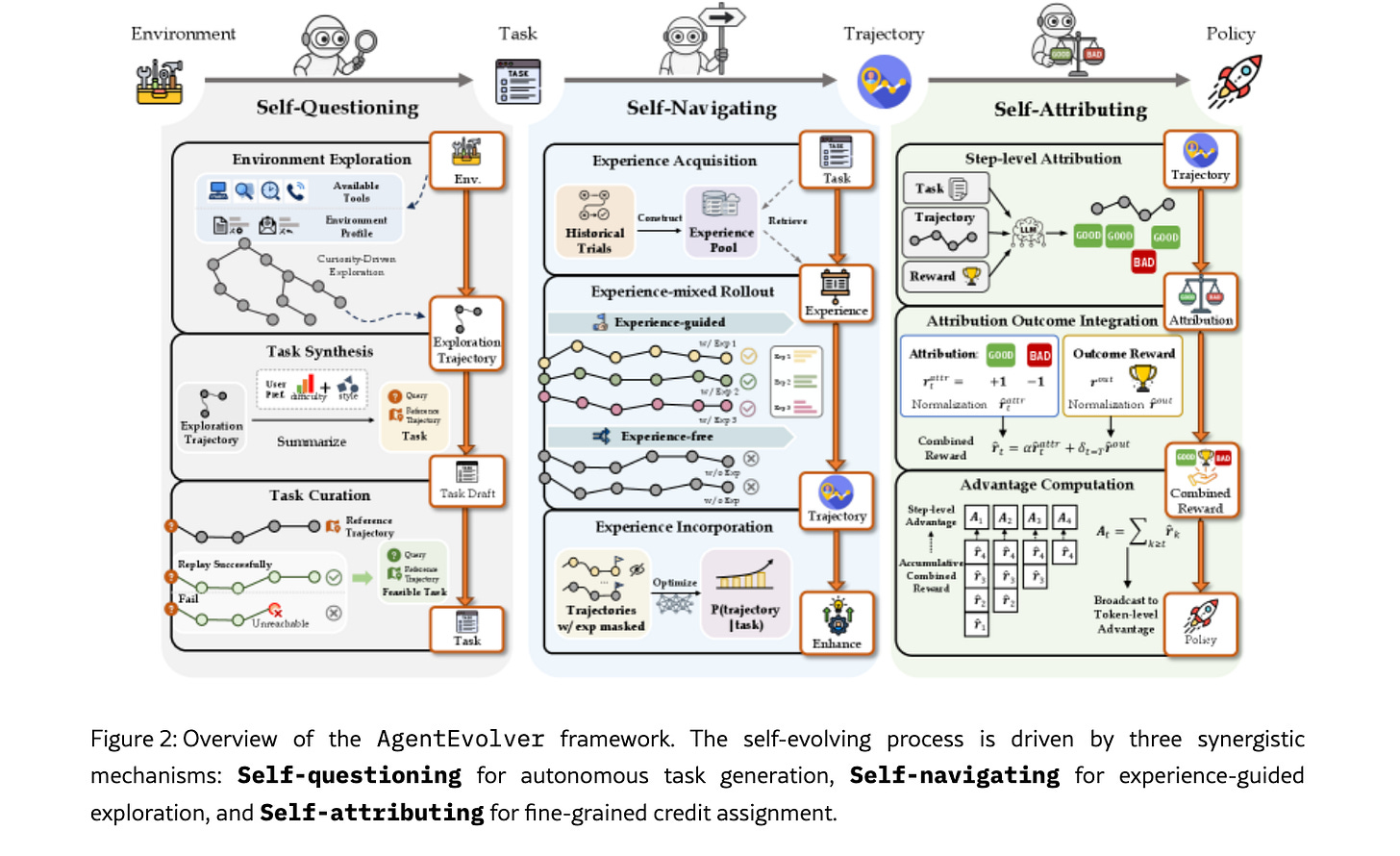
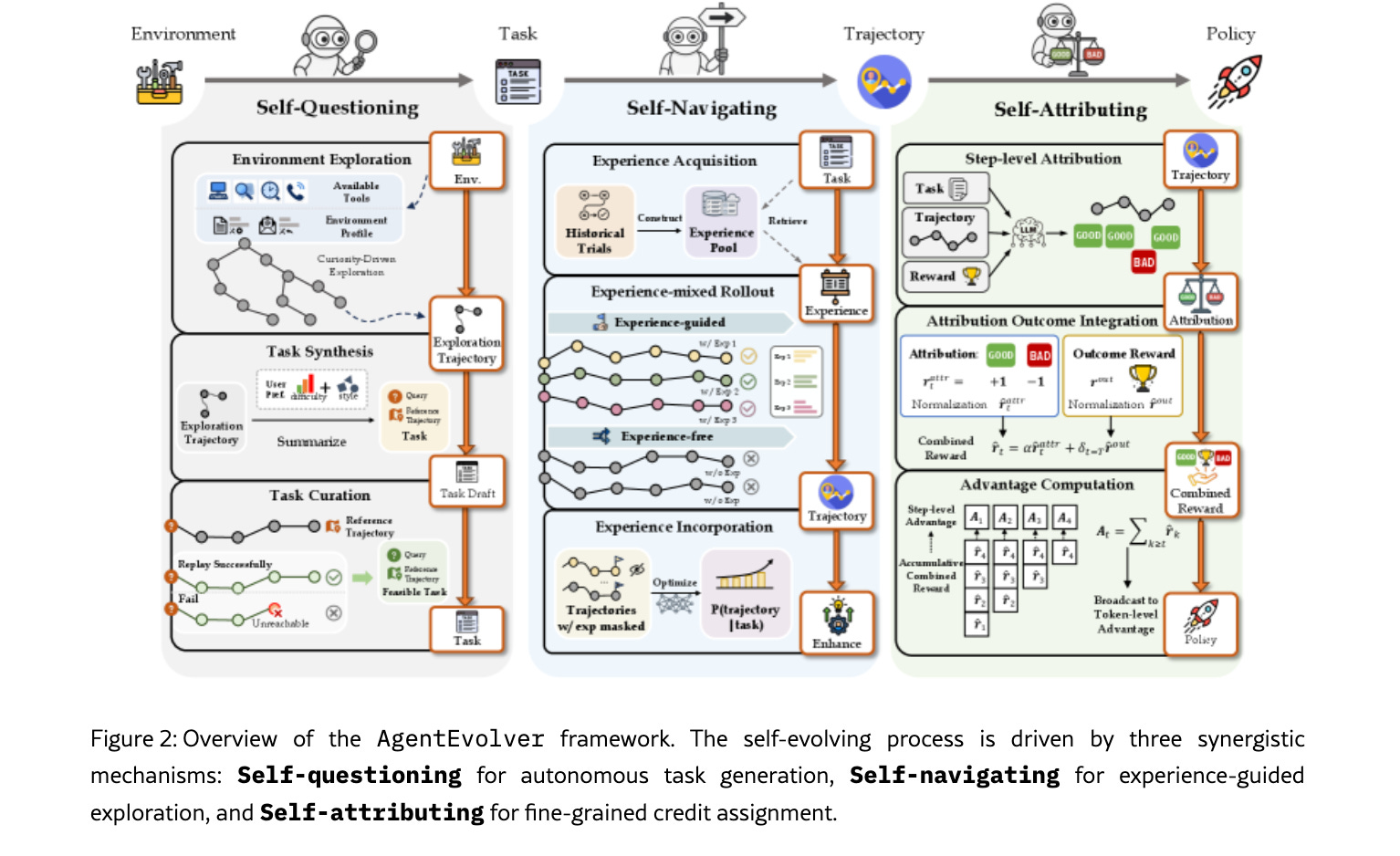
Alibaba’s Tongyi Lab took the loop a step further with AgentEvolver (co-authored by Alibaba’s chief scientist Zhou Jingren). Instead of just generating data, it automates the learning policy itself using three core pillars: self-questioning (curiosity-driven task generation), self-navigating (experience reuse), and self-attributing (differentiated credit assignment). It beats out much larger baselines on benchmarks like AppWorld while remaining incredibly parameter-efficient.
Shanghai AI Lab team runs massive reinforcement learning and agent programs. Their OS-agent research, including OS-Copilot, OS-Atlas, and OS-Genesis, is explicitly designed to build general, self-improving operating system agents.
AI-for-AI Research
Last year, researchers from Shanghai Jiao Tong University, SII, Taptap, and GAIR made a bold claim that they have created the first Artificial Superintelligence for AI Research (ASI-ARCH). This autonomous multi-agent system ran over 1,773 experiments spanning 20,000 GPU hours. It completely bypassed human-curated spaces and discovered 106 SOTA linear-attention architectures that outperform Mamba2.
On top of it, the same team is taking on a further challenge: Can AI automate the long-horizon, weakly supervised research loops that drive core AI progress? Their new framework, ASI-Evolve, introduces a closed “learn-design-experiment-analyze” loop. It enhances standard evolutionary agents with a cognition base (which injects human priors so the AI doesn’t start from scratch) and a dedicated analyzer (which distills chaotic experiment results into clean insights for the next round). The framework tries to discover breakthroughs across the three pillars of AI development:
Architectures: It discovered those 105 SOTA linear attention architectures mentioned earlier, with the best model beating human-designed DeltaNet by +0.97 points.
Data Curation: Its evolved data pipelines boosted average benchmark scores by +3.96 points, jumping a massive 18 points on MMLU.
Learning Algorithms: The algorithms it discovered beat out standard GRPO by up to +12.5 points on math benchmarks like AMC32.
Evolving Agent Skills
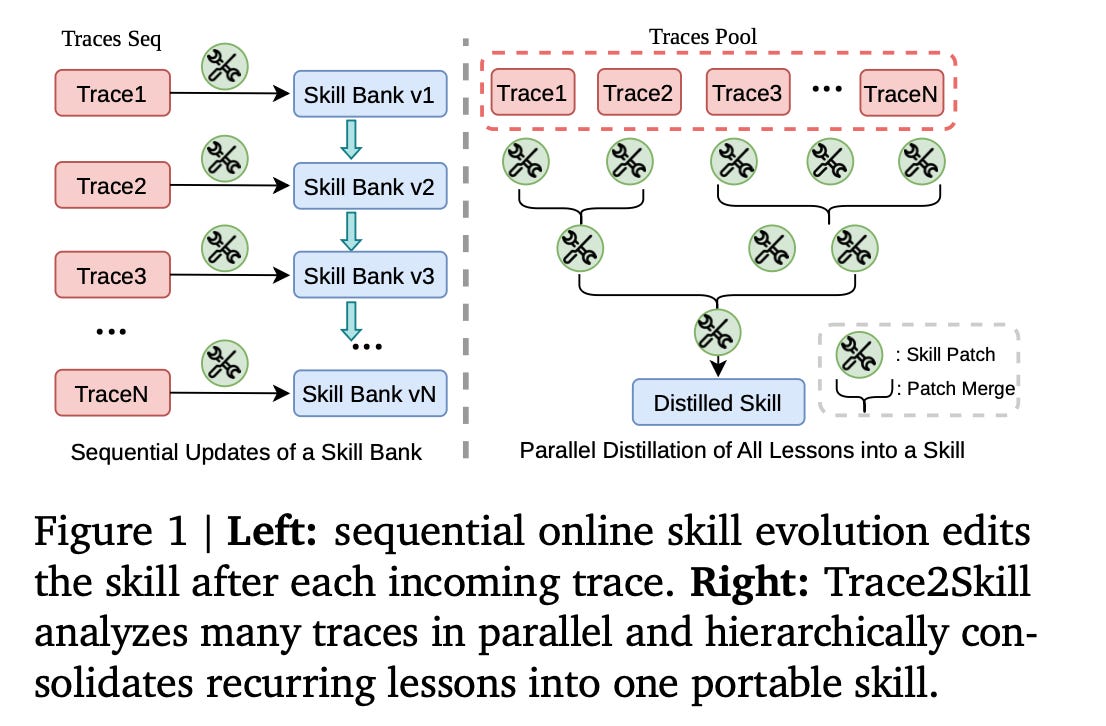
Recently researchers have been exploring how to improve and refine LLM’s external knowledge and skills at scale. Google’s ReasoningBank and Microsoft’s SkillOpt are typical research works. Researchers from Alibaba’s Qwen team proposed Trace2Skill where the framework can turn model trajectories into skills in parallel. It uses inductive reasoning across the agent’s experiences—both failures and successes—to distill recurring lessons into a single SOP. What’s interesting is the skills extracted from small models can help improve a much larger model. For instance, skills evolved from Qwen3.5-35B trajectories successfully improved a massive Qwen3.5-122B agent by a 57.65 percentage points on the WikiTableQuestions benchmark.
DeepSeek hasn’t released a dedicated self-improving AI research yet, but in their blockbuster DeepSeek-R1 paper, R1-Zero proved that a model trained purely on reinforcement learning—without any initial human supervised fine-tuning (SFT)—naturally evolves emergent self-reflection, real-time verification, the famous “aha moment,” and an autonomous allocation of longer thinking time.
Furthermore, a Bloomberg report last year highlighted DeepSeek and Tsinghua’s work on a strategy called self-principled critique tuning. Rather than relying on human annotators to align the model, the AI uses an automated internal rubric to reward responses that are both accurate and understandable. This method outperforms standard alignment benchmarks while using a fraction of the compute.
Ultimately, based on the researchers I’ve spoken with and the latest ICLR workshop discussions, there is no major divergence between the US and China when it comes to the direction of self-improving AI. Researchers from both countries are focused on the similar playbook: optimizing loops to let models update their own weights, and engineering self-evolving agents that can interact with and adapt to the complex environments.
The real gap isn’t the strategy but the underlying foundation models. Because a self-improvement loop is only as smart as its foundation, whoever possesses the superior base foundation model inherently has a much higher probability of successfully upgrading it.