
🤔DeepSeek-V4 Doesn't Have to Win to Matter
DeepSeek-V4 may not be the best open LLM, but its architectural innovations will lift the entire open ecosystem.


The long-anticipated DeepSeek-V4 has finally arrived, released in the same laast week as OpenAI’s GPT-5.5, Moonshot’s K2.6, and Tencent’s Hunyuan 3 preview, probably the most intense moment in the current model race.
The preview open-source releases include two versions:
DeepSeek-V4-Pro features 1.6 trillion total parameters with 49 billion active parameters, making it even more sparse than DeepSeek-V3, pre-trained on 33 trillion tokens.
DeepSeek-V4-Flash features 284 billion total parameters with 13 billion active parameters, a lighter model for the majority of developers who can’t deploy the gigantic Pro version. Pre-trained on 32 trillion tokens.
The selling point of the DeepSeek-V4 series is a one million token context window at an affordable price, laying the foundation for models handling long-horizon agentic tasks that require holding enormous amounts of information in memory without losing the thread. To get there, DeepSeek introduced new architectural innovations and incorporated techniques like mHC and the Muon optimizer.
On pricing, DeepSeek-V4 charges $1.74/$3.48 per million input/output tokens, while Claude Opus 4.6 charges $5/$25. The price advantage narrows against other Chinese open LLMs as Zhipu’s GLM 5.1 charges $1.4/$4.4 per million tokens, though the model doesn’t offer the 1M context window. DeepSeek also just slashed cache hit prices across its entire API to one-tenth of the original price, and the V4-Pro 75% off promotion runs through May 5, 2026.
On performance, DeepSeek-V4-Pro is strong at math (HMMT 2026 and IMOAnswerBench) and competitive programming (Codeforces and LiveCodeBench)—the kind of coding that solves well-defined problems with known solutions. On knowledge, DeepSeek also leads all open models by a wide margin, though Gemini 3.1 Pro is aheaad.
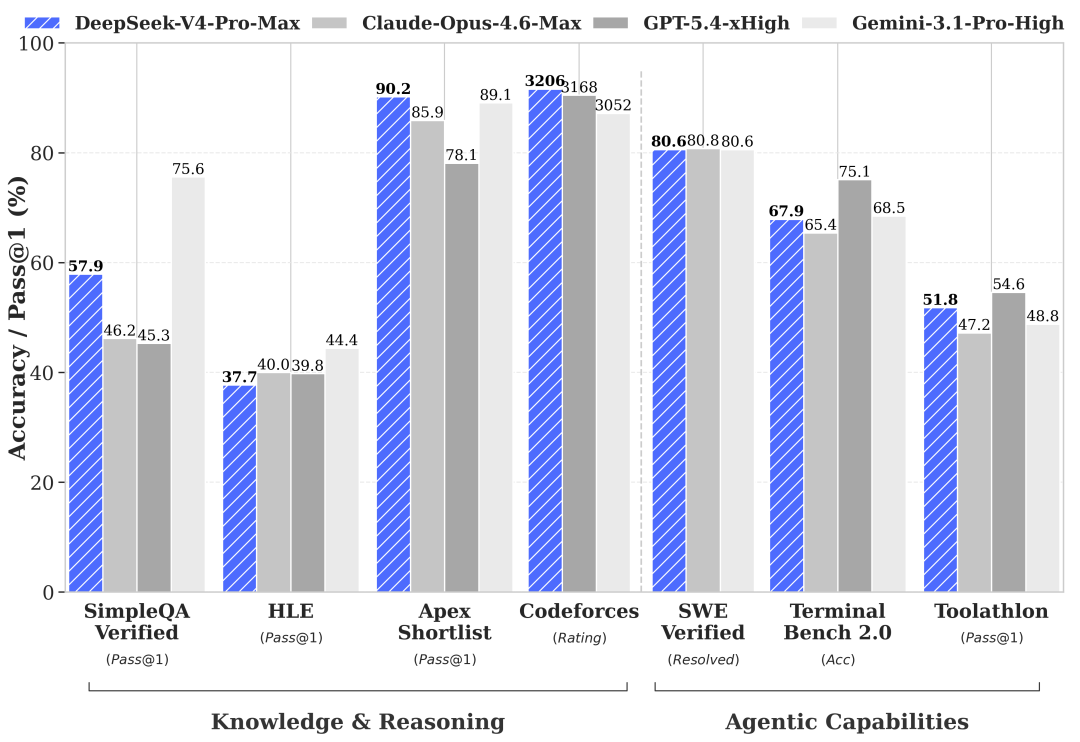
But it still lags top frontier models on real-world software engineering (SWE Pro) and agentic tasks (HLE with tools). The company admits in its technical report that its reasoning trails the top frontier models by roughly three to six months. On Chatbot Arena and Artificial Analysis, V4 ranks among the best open models but trails Kimi K2.6 and Xiaomi’s MiMo V2.5 Pro.

Also noteworthy: DeepSeek has optimized V4 for Huawei’s Ascend AI chips. Current serving throughput for V4-Pro is limited, but the company expects pricing to drop significantly in the second half of the year once Ascend 950 supernodes ship at scale.
Architectural Innovations to Drive Down the Cost of 1M Tokens
While DeepSeek-V4 didn’t make as big a splash as V3, it is in my view the most architecturally ambitious model the lab has released. The backbone remains familiar—DeepSeek MoE and multi-token prediction—but nearly everything built on top of it is new.
In my earlier predictions, I thought V4 might just continue using DeepSeek Sparse Attention (DSA). What surprised me is that DeepSeek pushed further than DSA by proposing an entirely new hybrid attention architecture, the core innovation that makes cheap 1M token processing possible.
Standard attention scales quadratically with context length. At one million tokens, the compute and memory costs make it impractical to serve at scale. Breaking that bottleneck is the core problem DeepSeek V4 was built to solve.
DeepSeek designed two complementary attention mechanisms and interleaves them across the model’s 61 layers.
CSA (Compressed Sparse Attention): Instead of attending to every token, CSA first compresses every group of 4 tokens into one condensed entry using learned weights — the model figures out during training what’s worth keeping. Then a fast lookup system called the “lightning indexer” identifies which compressed chunks are actually relevant to the current query, and the model attends only to those. A small sliding window of recent uncompressed tokens is also kept, so local context isn’t lost.
HCA (Heavily Compressed Attention): More aggressive. It compresses every 128 tokens into a single entry and attends to all of them densely, without any sparse selection. Less precise, but extremely cheap.
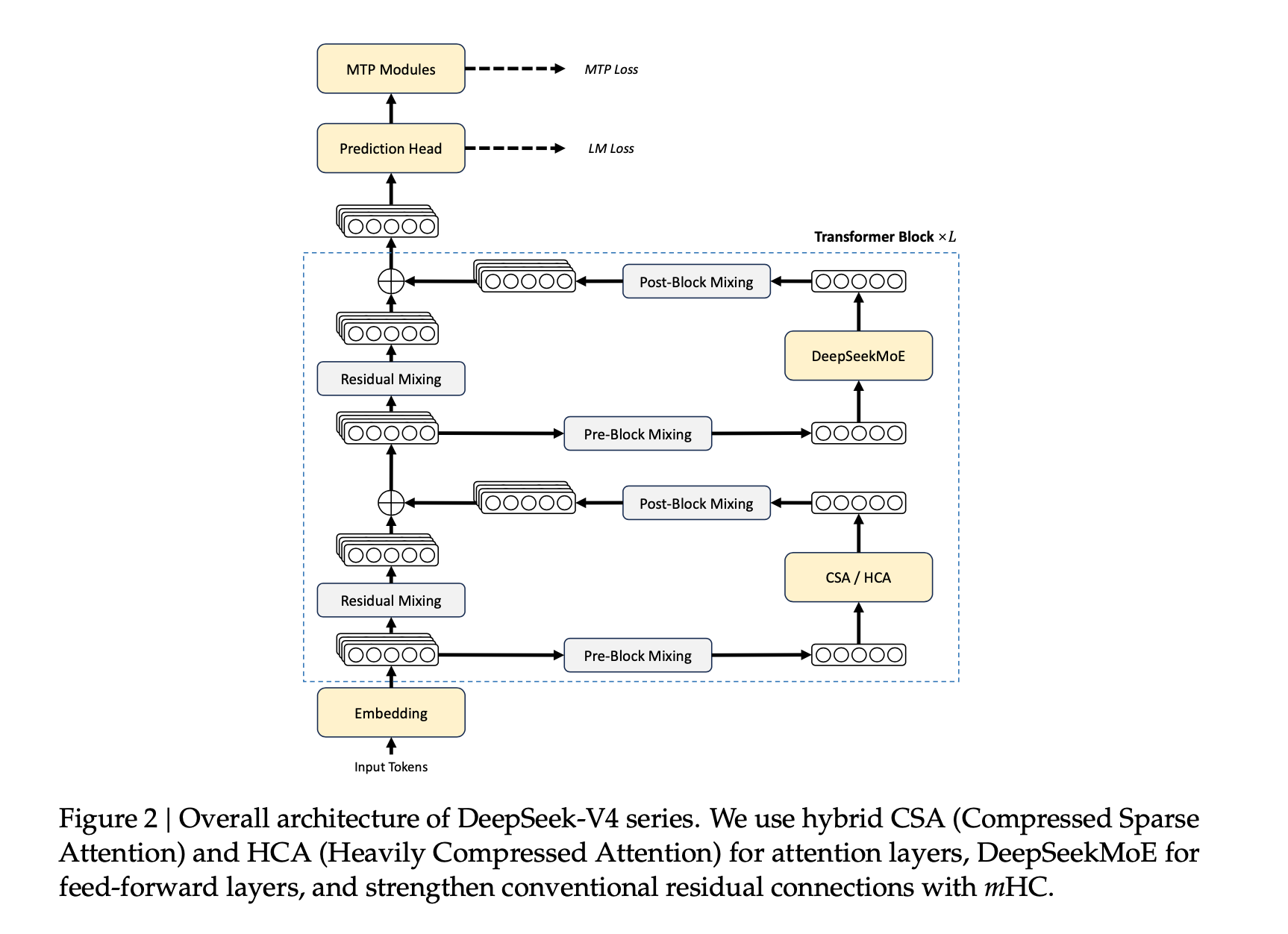
The combination works because CSA handles nuanced, selective retrieval while HCA handles the broad sweep cheaply. Together they cover different retrieval needs at different computational costs. The paper reports that at one million tokens, V4-Pro needs only 27% of the inference compute and 10% of the KV cache—the memory used to store context—compared to V3.2.
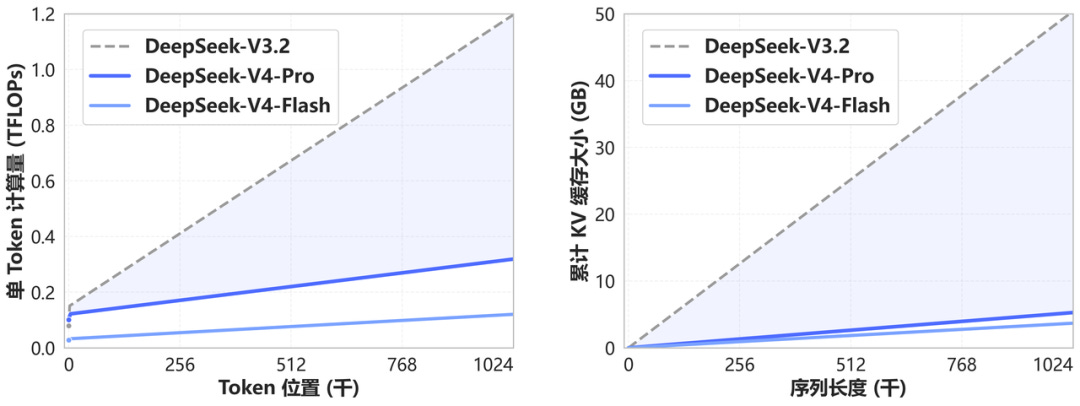
There is a cost of course. The benchmark gaps on MRCR and CorpusQA—both long-context retrieval tests—versus Claude Opus 4.6 suggest some information loss from the compression. But for most tasks, what gets compressed away seems not to matter. The 10x memory saving is worth the marginal retrieval gap on the hardest benchmarks.
The first two layers of V4-Pro use HCA only, then the interleaved CSA-HCA pattern runs through the remaining layers, according to the paper.
On top of attention, mHC (Manifold-Constrained Hyper-Connections), which I explained in a previous post, is employed to strengthen residual connections between layers. Normally, information flows through a neural network layer by layer through a single residual stream—one pipe carrying signal from layer to layer. mHC widens that pipe to four parallel streams, giving each layer more flexibility in how it draws from and contributes to the information flow. The “manifold-constrained” part is the stability fix: without it, multiple streams stacked across dozens of layers cause signals to explode or vanish during training. DeepSeek’s innovation was to mathematically constrain the mixing between streams so the model stays stable without without giving up any of the intelligence gains. In plain terms: wider pipe, guardrails on the pipe.

The Muon optimizer is the third major innovation, and it comes with an interesting story. Muon was originated in the open-source research community and was notably scaled for LLM training by Moonshot AI for its Kimi models. DeepSeek adopted it for V4.
Most large models train using an optimizer called AdamW, which updates each weight independently based on its own history. Muon treats the weight matrices more holistically, making each update geometrically cleaner relative to the weight matrix as a whole, through a technique called Newton-Schulz iterations. The result is faster convergence and better training stability, both meaningful at a scale of 33 trillion training tokens.
The deeper point is that DeepSeek and Moonshot are rivals in AI race. Yet Moonshot has largely borrowed DeepSeek’s architecture since Kimi K2, and DeepSeek is now using Moonshot’s optimizer. This open-source practice as mutual adoption between competitors further benefits the whole ecosystem.

One thing I was hoping to see that didn’t make it: Engram, DeepSeek’s memory architecture, and multimodality. The paper is candid about why:
In pursuit of extreme long-context efficiency, DeepSeek-V4 series adopted a bold architectural design. To minimize risk, we retained many preliminarily validated components and tricks, which, while effective, made the architecture relatively complex. In future iterations, we will carry out more comprehensive and principled investigations to distill the architecture down to its most essential designs.
We are also working on incorporating multimodal capabilities to our models.
Infrastructure Improvement and Post-Training
Infrastructure is arguably where DeepSeek excels, and V4 is no exception.
On training efficiency, they proposed a fine-grained EP scheme that fuses communication and computation into a single pipelined kernel for communication-computation overlapping, achieving up to 1.96x speedup for latency-sensitive workloads like RL rollout, and validated it on both NVIDIA GPUs and Huawei Ascend NPUs.
They adopted TileLang, a domain-specific language for writing GPU kernels that lets researchers prototype operators quickly and optimize the same code for production without rewriting it from scratch.
On precision, they trained with FP4 quantization awareness from the start rather than applying it after the fact. The model runs faster and uses less memory at deployment without meaningful performance loss. The paper notes FP4 could be a further one-third more efficient on future hardware.
Finally, they designed a custom KV cache layout to handle the heterogeneous memory requirements of mixing CSA and HCA layers, and built on-disk KV cache storage so that shared-prefix requests—many users sending similar long prompts—only pay the expensive prefill cost once.
DeepSeek-V4’s post-training pipeline ran in two stages.
Specialist training: they built separate expert models for each domain—math, coding, agents, instruction following—each fine-tuned on domain-specific data and then sharpened with reinforcement learning. They also trained three reasoning effort modes (Non-think, High, Max) by varying how much thinking budget each mode gets during RL.
On-policy distillation: rather than merging specialists through weight averaging, which degrades performance, or mixed RL, which is unstable, they trained a single student model to learn from more than ten specialist teachers simultaneously by mimicking their output distributions on its own generated text. The key technical choice was full-vocabulary logit distillation rather than a token-level approximation, which produces more stable gradients and more faithful knowledge transfer.
V4 Doesn’t Have to Win to Matter
The lukewarm reception to V4, especially in Silicon Valley, is probably unsurprising. Anthropic and OpenAI are releasing powerful closed models, and the gap between the best open models and the best closed-source models may not be narrowing. Even among Chinese open LLMs, V4 is not a clear win.
But the implications of V4 may take time to show up. After V3 and R1, most major open LLMs adopted or borrowed DeepSeek’s architecture to make their models more efficient, and as a result open models in 2025 broadly improved without everyone having to independently experiment.
Entering 2026, against the backdrop of global compute shortage as agentic token usage skyrockets, V4’s memory and inference efficiency innovations could ease real constraints if adoption grows. It might take another three to six months to see V4’s architectural innovations diffuse across the open ecosystem.
What I find worth noting is that while every other major lab is racing to release models and eke out marginal leaderboard gains, DeepSeek-V4 still prioritized architectural exploration over benchmaxxing. New architectures are risky. They can destabilize training and waste compute. But the bet is consistent with a lab that believes the path to AGI runs through efficiency and democratization, not through scaling alone (partly also due to the export control on advanced chips).
DeepSeek is also navigating real pressures. It’s aiming to raise funding at a valuation exceeding $20 billion, with Alibaba and Tencent both said to be interested. The new capital would help the company access more compute for training and retain top talent. DeepSeek CEO Liang Wenfeng is also reportedly hiring more product managers and building new consumer products.
DeepSeek’s V4 release post closed with a line from the Chinese philosopher Xunzi:
不诱于誉,不恐于诽,率道而行,端然正己。Unseduced by praise, undaunted by slander; following the Way, standing upright in oneself.
(The English translation is attributed to Kevin Xu.)
The road ahead for DeepSeek won’t be easy as the AI race intensifies. But a company this consistent in its long-termism—and this committed to keeping its research open—gives me more reason for optimism about where AI is heading.
Thank you Tony 🙏 Deepseak follow it's own path. Good for humanity ✌️
不诱于誉,不恐于诽,率道而行,端然正己