
🗣️DeepSeek-V3.2: Outperforming Through Verbosity
With Nvidia H200 available for sale to China, will DeepSeek accelerate its pre-training progress?


DeepSeek last week released its latest LLMs DeepSeek-V3.2 and V3.2-Speciale, an unrefined, long thinking version. The company claimed V3.2-Speciale surpassed GPT-5 on reasoning tasks and snagged gold medals at both the 2025 International Mathematical Olympiad and the International Olympiad in Informatics.
While this comes as the wildly-anticipated DeepSeek-V4 and R2—supposedly DeepSeek’s next-gen foundation model and reasoning model—remain delayed, DeepSeek-V3.2 still shipped some interesting innovations.
The paper lays out three core contributions:
A sparse attention mechanism that cuts computational complexity for long contexts.
A reinforcement learning (RL) framework scaled to over 10% of pre-training compute.
A synthetic data pipeline that auto-generates 85,000 agent tasks across 1,800 environments.
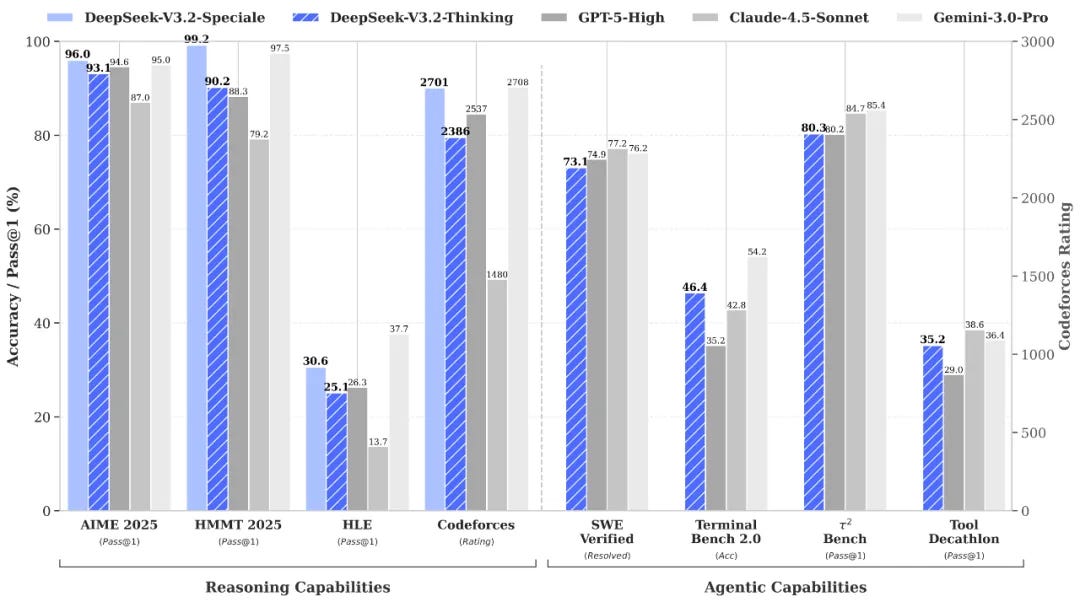
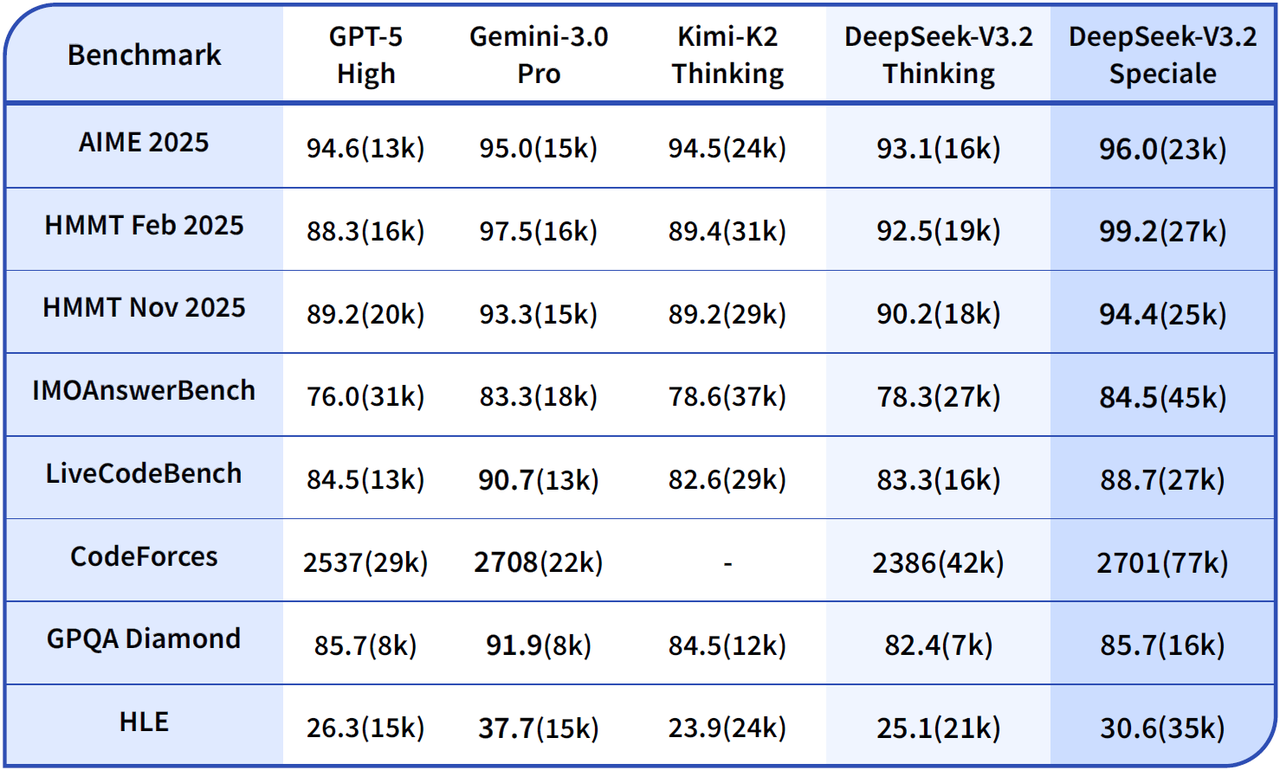
V3.2’s performance puts it solidly in frontier territory. On reasoning benchmarks, it hits 93.1% on AIME 2025, 92.5% on HMMT, and 30.6 on HLE. That’s close to GPT-5-High, though still noticeably behind Gemini 3.0-Pro. Agentic performance is competitive too as it reaches 73.1% on SWE-Verified, 46.4% on TerminalBench 2.0.
V3.2-Speciale takes this further. It outperforms Gemini-3.0-Pro with 96.0% on AIME and 99.2% on HMMT, hits 84.5% on IMOAnswerBench, and gets gold medals across IMO 2025, CMO 2025, IOI 2025, and ICPC World Finals 2025.
DeepSeek V3.2 is also the second smartest open weights model on Artificial Analysis Intelligence Index. It closely trails Kimi K2 as the model featuring 671 billion total parameters and 37 billion active parameters is smaller than K2.

As always, DeepSeek-V3.2’s API pricing is absurdly low. It costs $0.28 per million input tokens, $0.42 per million output tokens. With caching, input costs can drop to $0.028 per million tokens.
The Sparse Attention
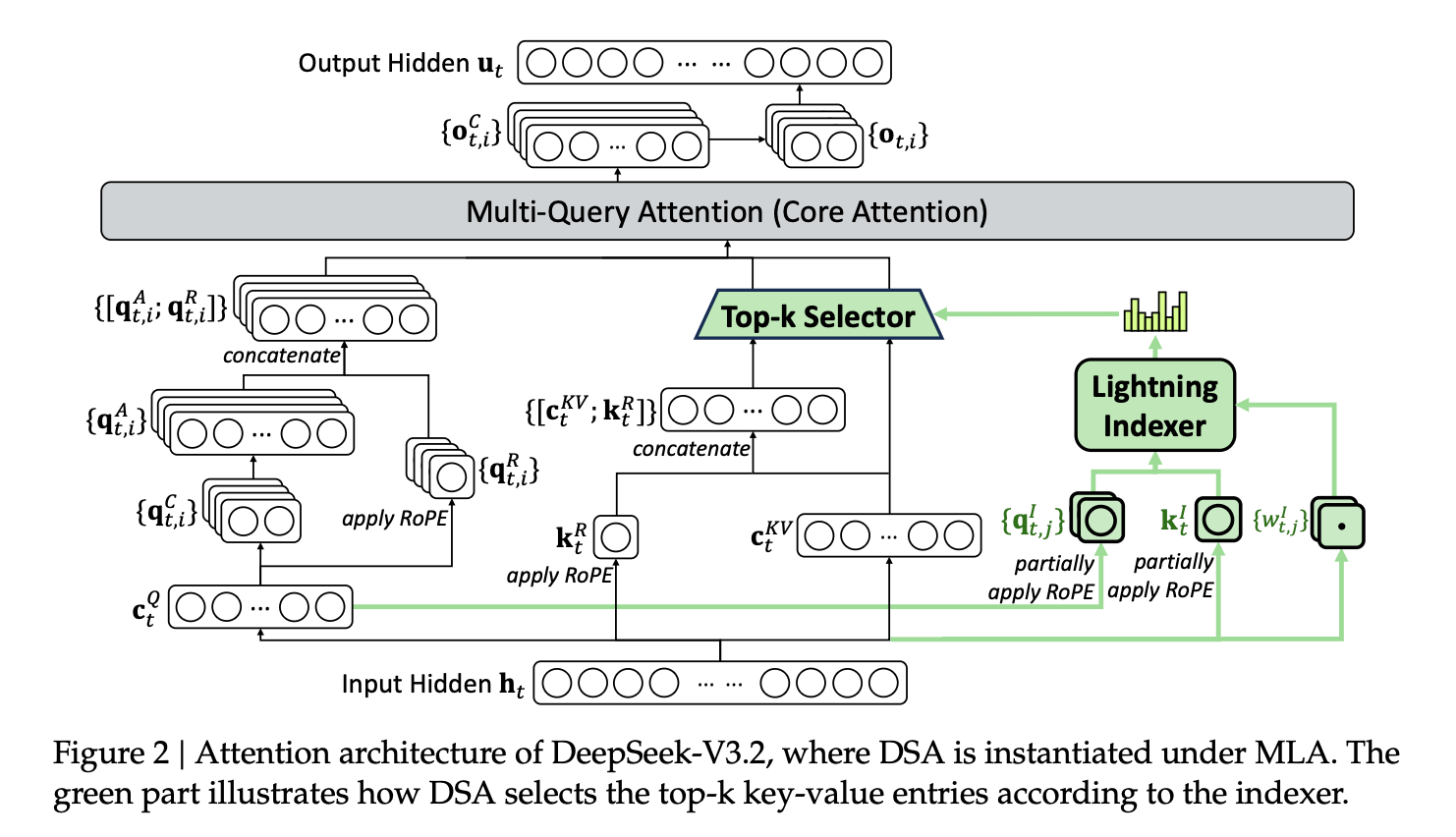
The only architectural modification between DeepSeek-V3.2 and DeepSeek-V3.1 is DeepSeek Sparse Attention (DSA).
The traditional full attention mechanisms look at every single token in context. It’s thorough but computationally complex for long contexts, like reading every word in a textbook when you’re looking for one specific concept. DSA uses what they call a Lightning Indexer to score tokens first, then only pays full attention to the (top-k) most relevant ones.
Think of it as skimming before you read. The indexer runs cheap (FP8 precision, minimal parameters), picks what matters, then the model does full attention only on those selected tokens. This results in less compute, similar quality, faster training and inference.
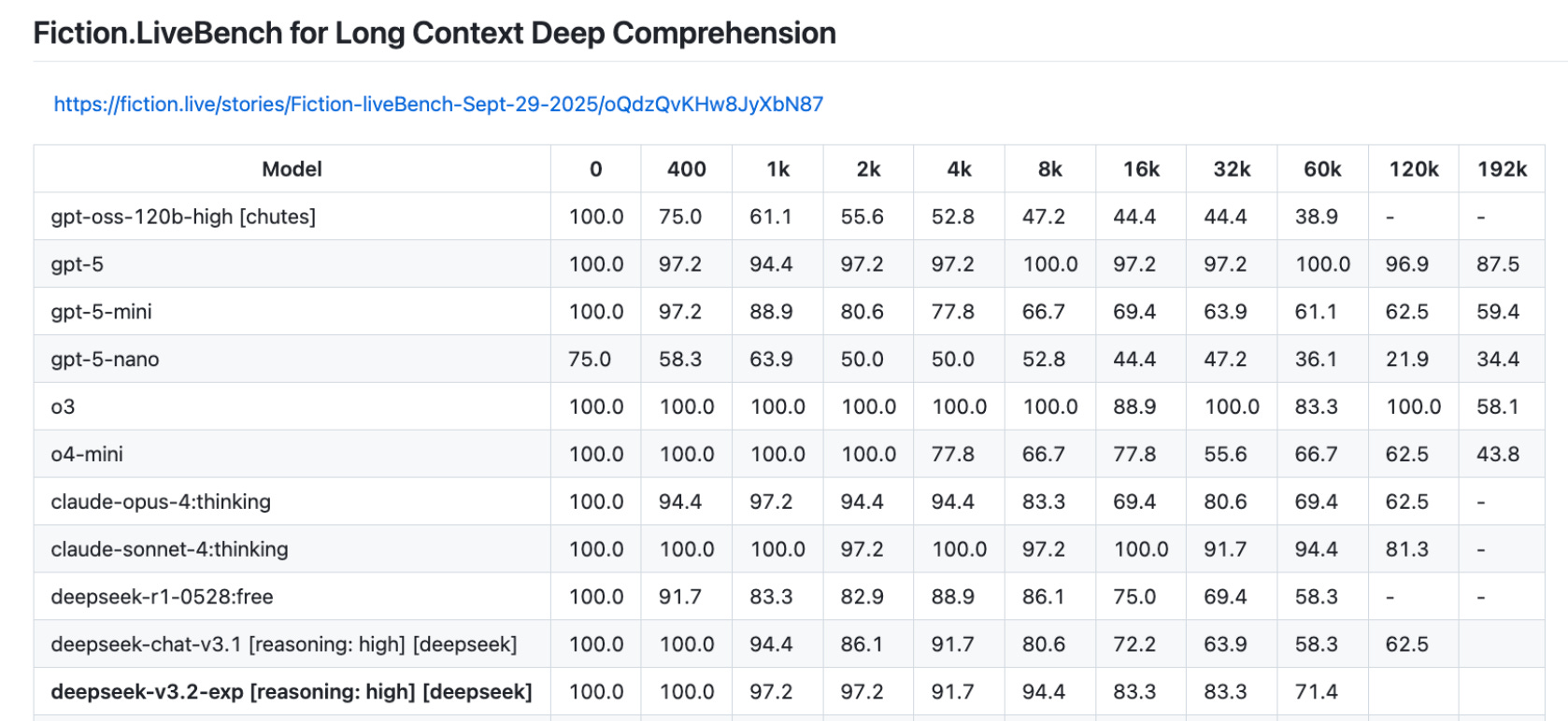
On Fiction.LiveBench, which assesses a model's ability to retrieve details from long-context texts for deep comprehension, DeepSeek-V3.2-exp—an experimental version released in September that also adopts DSA—performs exceptionally well among all open-weight models.
DSA works well with DeepSeek’s previous innovation, Multi-head Latent Attention (MLA), which already compressed key-value representations to drastically reduce memory and computation. Now DSA decides which of those compressed representations actually deserve attention. It’s efficient storage meeting efficient selection.
Scaling Post-Training Through RL
Since DeepSeek-R1, DeepSeek has been doubling down on how to squeeze better performance through post-training of the model.
They trained specialist models for math, programming, logic, agent tasks, and search, then distilled those into the base model. Then came the RL phase, which used a strikingly over 10% of their total pre-training compute budget. The authors believed reasoning capabilities could be further improved with more budget for post-training.
Their RL setup merges reasoning, tool-use, and alignment into one training stage, using outcome-based rewards including correctness, tool success, reasoning clarity alongside penalties for verbosity.
They built in safeguards, including unbiased KL estimators, off-policy masking, and keep-routing for MoE stability, to prevent the training from going off the rails. Tweeted DeepSeek research Gou Zhibin,
If Gemini-3 proved continual scaling pretraining, DeepSeek-V3.2-Speciale proves scaling RL with large context. We spent a year pushing DeepSeek-V3 to its limits. The lesson is post-training bottlenecks are solved by refining methods and data, not just waiting for a better base.
The Verbosity Problem
Multiple researchers are reporting that V3.2-Speciale burns through tokens at an alarming rate. For the same task, Gemini uses 20,000 tokens while Speciale uses 77,000. On Artificial Analysis Intelligence Index, V3.2-Speciale generated 160 million tokens, which is significantly more verbose than the average of 22 million tokens. Even the refined V3.2 version is considered verbose by generating 86 million tokens.
What’s worse is the model sometimes produces long, rambling answers that are still wrong. It’s a known issue with GRPO (Group Relative Policy Optimization), the RL algorithm DeepSeek used. A recent paper, Understanding R1-Zero-Like Training: A Critical Perspective, points out that GRPO’s reward normalization inadvertently rewards length, especially for incorrect outputs. The model learns verbosity instead of correctness.
The paper clarified that V3.2-Speciale was trained exclusively on reasoning data with a reduced length penalty during RL. It’s intended for research purposes only and not optimized for daily use.
Making Tool Calls Part of Reasoning
The last contribution is DeepSeek figured out how to keep the model’s chain-of-thought intact across multiple tool calls.
Earlier methods wiped the reasoning slate clean every time a model used a tool, whether search the web, run code, or query a database. The model had to restart its thinking from scratch each time, which wasted tokens and broke long-horizon planning.
V3.2 keeps the reasoning thread alive unless a new user message arrives. Tool outputs don’t erase previous thoughts. The model sees the entire trajectory as one continuous process. This also echos interleaved thinking from Moonshot AI’s K2-Thinking and MiniMax’s M2.
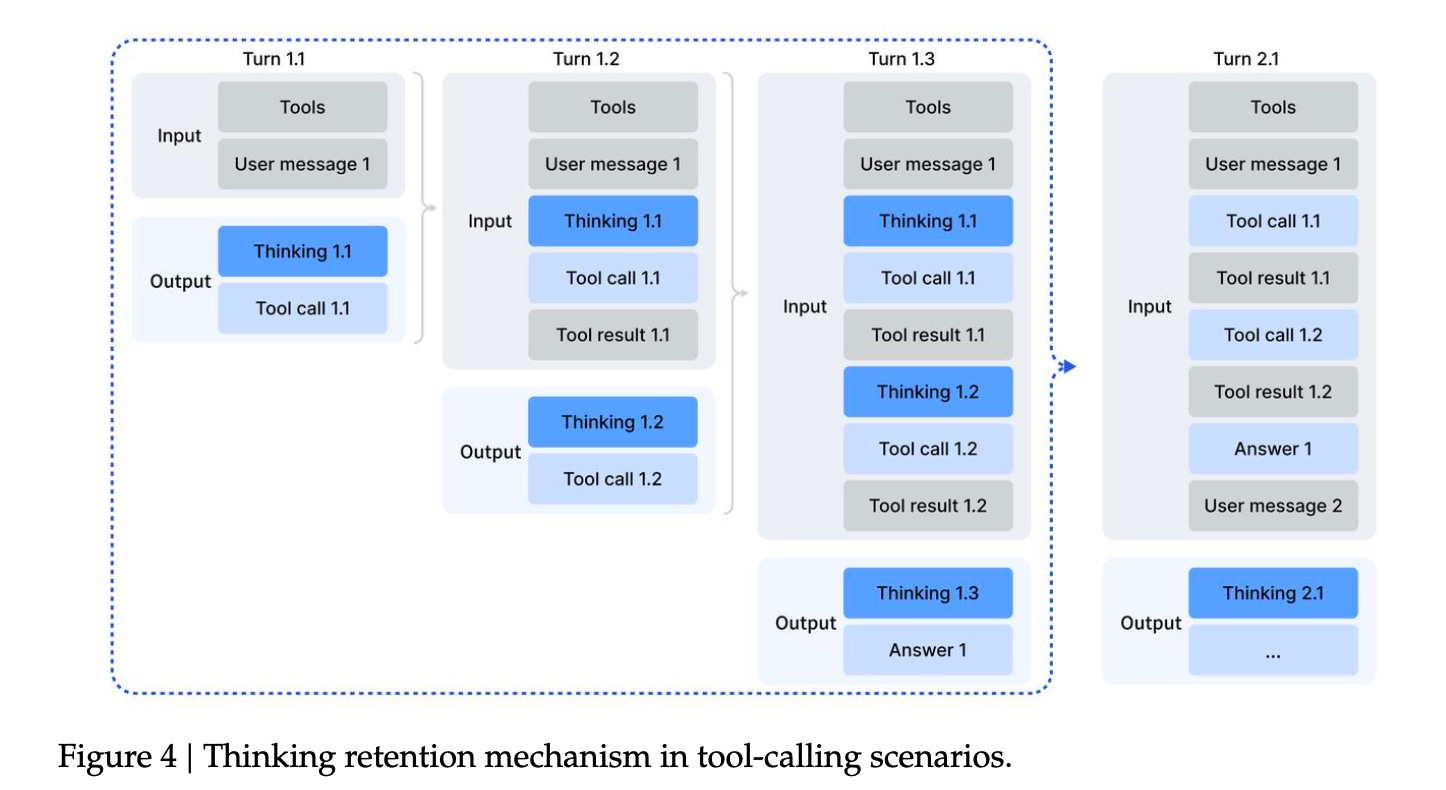
This matters for agentic behavior. The model can actually plan across multiple steps instead of constantly rebooting its reasoning engine.
To train these agent capabilities, DeepSeek built a massive synthetic data pipeline including 1,800+ environments and 85,000 complex tasks, all auto-generated and auto-verifiable.
The system works recursively. The model builds environments, creates tool APIs, generates tasks, and writes verification functions. They also used real tools—web search, coding sandboxes, GitHub repos, Jupyter notebooks—to create verifiable trajectories for search and coding agents.
Limitations and Key Takeaways
Despite the progress, DeepSeek remains honest about the gaps against leading proprietary models:
World knowledge is still weaker. V3.2 used less pre-training compute than Gemini-3.0-Pro or GPT-5, so its breadth and depth of general knowledge lag behind frontier proprietary models.
Token efficiency is poor. The model needs longer reasoning chains to hit the same performance benchmarks as competitors.
The hardest tasks still win. On truly complex, long-horizon problems, V3.2 still falls short of top proprietary models. The authors think this needs more pre-training compute, more RL compute, better task design, and further architectural refinement.
DeepSeek-V3.2 continues to embody DeepSeek’s signature research style: an obsession with pushing computational cost-effectiveness to the extreme. In the meantime, the team keeps scaling post-training to squeeze out every bit of performance from the model. This is also a strategy that aligns naturally with China’s AI landscape, where access to advanced GPUs remains limited and domestic chips tend to be optimized for inference rather than large-scale training.
The authors also said they plan to expand pre-training compute in future iterations. Gemini 3.0 Pro has already shown that scaling pre-training still pays off. More compute and more data can translate into more intelligence and stronger reasoning and better performance on increasingly complex tasks.
Just as I was about to release this issue, U.S. President Donald Trump announced that Nvidia will be allowed to ship its H200 AI chips to “approved customers” in China and elsewhere, on the condition that the U.S. receives a 25% cut. The Chinese leader “responded positively.”
If this policy holds, and the Chinese government gives the greenlight as well, it would be a major boost for Chinese companies with frontier AI labs such as Alibaba, ByteDance, and DeepSeek, which reportedly delayed the release of their new models after being unable to train them successfully on Huawei’s AI chips.
The interesting part isn’t V3.2’s benchmarks, it’s the strategic pattern.
China’s labs are learning to convert compute scarcity into coordination advantage:
aggressive post-training
tool-integrated reasoning
synthetic agent environments
When intelligence cheapens, the real frontier becomes how well a system organizes itself across tools, tasks, and trajectories.
DeepSeek is basically running the “coordination over compute” playbook at national scale.