
👐🏻As Anthropic Tightens Access, Chinese AI Labs Open Their Models
How MiniMax, Zhipu, and Moonshot capitalized on the sudden U.S. ban on Anthropic's Mythos & Fable models by releasing M3, GLM-5.2, and K2.7-Code.


When Anthropic abruptly suspended all access to its newly released Mythos 5 and Fable 5 models last Friday following an unexpected U.S. government ban on foreign nationals using these models, Chinese AI labs quickly capitalized on the opportunity. They released new open-weight models and sent a message: Their AI will remain open to the world.
For background, Mythos 5 and the safeguarded Fable 5 are Anthropic’s most powerful models to date, having just launched last week. Rumored to feature a staggering 10 trillion parameters, they achieved SOTA results on most benchmarks. However, Anthropic warned that the models pose cybersecurity risks—specifically the ability to autonomously find and exploit software vulnerabilities—which reportedly triggered the U.S. government’s sudden intervention.
Here is how Chinese labs are responding to the vacuum.
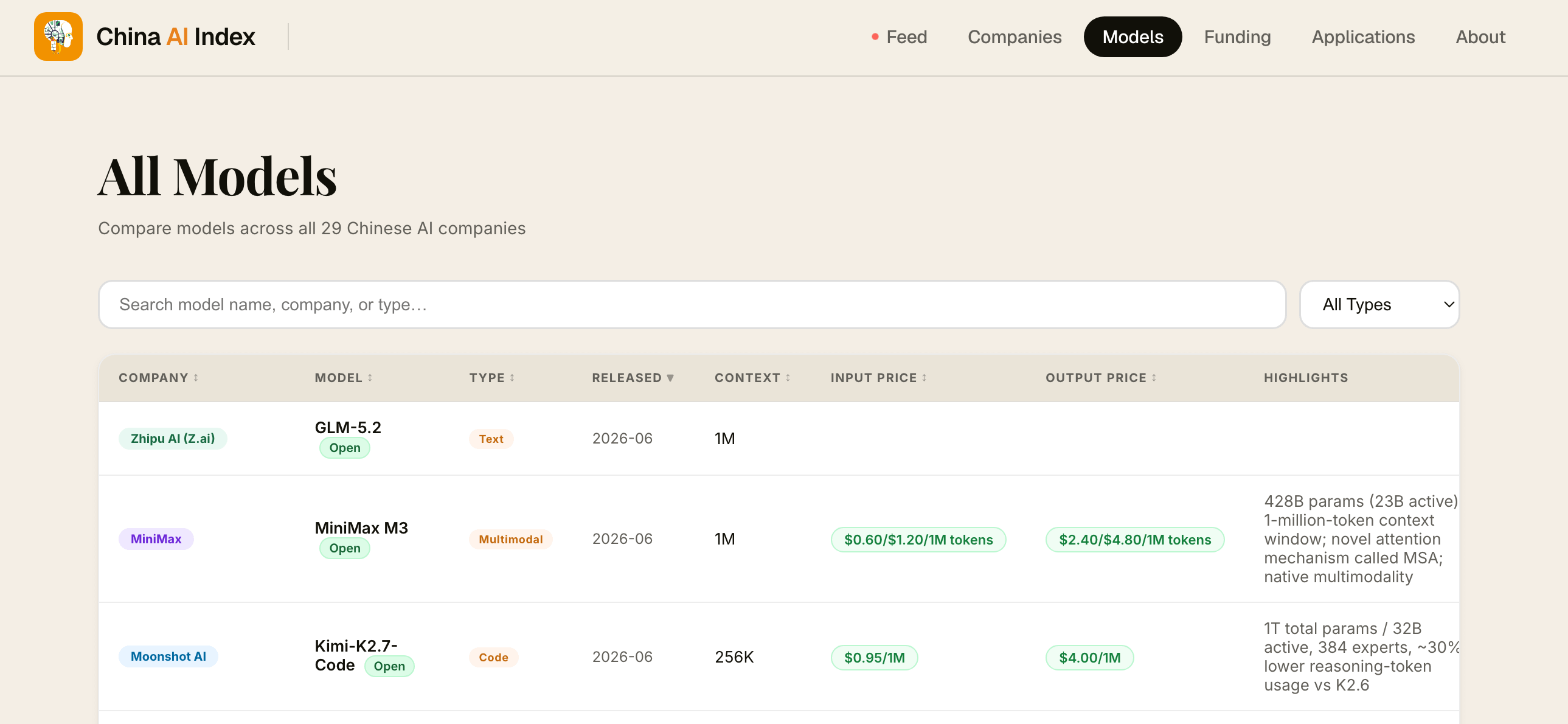
MiniMax Open-Sources M3

First up is MiniMax. The Hong Kong-listed AI company introduced its latest flagship model, MiniMax M3, a week ago and on Friday opened its weights. As the company’s first multimodal flagship, M3 performs on par with GPT-5.5 in coding, agentic information retrieval, and physics-based reasoning.
Surprisingly, the model is incredibly small. It features only 428 billion total parameters, activating only 23 billion parameters per inference run. For context, DeepSeek-V4-Pro features over 1.6 trillion parameters.
The model supports a 1M-token context window, thanks to its new proposed attention mechanism called MiniMax Sparse Attention (MSA). The company said MSA can partition the KV into blocks more precisely compared to DeepSeek Sparse Attention (DSA).
Ryan Lee, Head of Developer Relations at MiniMax, tweeted about the architectural choice:
We’ve been discussing what parameter size works best for the community. While the M3 series boasts a larger parameter count compared to the M2 lineup, we’ve kept its scale deliberately restrained so local model enthusiasts can run it affordably. This time we settled on 428B, hoping it will be accessible to a wider audience.
The moment news of the Fable and Mythos restrictions broke, MiniMax quickly retweeted Anthropic, implying they would never lock out users.


Zhipu AI (Z.ai) Drops GLM-5.2
Next came Zhipu AI’s announcement of GLM-5.2. Friday night in the U.S. (Saturday afternoon in Beijing) is usually a terrible time to drop a flagship LLM, but Zhipu pushed ahead anyway.
The company said GLM-5.2 is already rolling out to its Coding Plan users, adding that intelligence should be open and accessible to empower developers everywhere.



Zhipu’s co-founder and Chief Scientist, Tang Jie, took a more direct stance on X:

A very interesting detail: According to Anthropic’s statement, they received the U.S. government’s legal directive to pull the plug on their models on Friday at 5:21 PM ET. Zhipu timed the rollout of GLM-5.2 to Coding Plan users at exactly 5:21 PM, Beijing Time, the next day, according to a popular Chinese AI influencer.
The model’s full rollout is targeted for later this week. I will update this post with technical details and pricing once it goes live. What we know so far is that GLM-5.2 supports a 1M-token context window and leads in long-horizon tasks (complex tasks executed over long periods). This remains a text-only model though, not a multimodal one.
Zhipu AI’s stock price surged as much as 48% today, as JP Morgan raised its target price to HK$1400 from HK$950.
Moonshot AI Releases Kimi-K2.7-Code

Moonshot AI also released a new specialized coding model called Kimi-K2.7-Code. The company boasted notable improvements over its predecessor, K2.6, in coding and agent performance: +21.8% on Kimi Code Bench v2, +11.0% on Program Bench, and +31.5% on MLS Bench Lite (it’s worth noting these are less widely recognized benchmarks).
The model’s pricing is at $0.95 per million input tokens and $4.00 per million output tokens.
The 1T-param model is 30% less verbose than K2.6. As token efficiency becomes an important metric for enterprise clients looking to lower AI inference costs, conciseness is becoming a major selling point. I plan to write a piece on this trend next week. K2.7-Code also features improvements in long-horizon coding tasks.
Alongside the model, Moonshot launched the Kimi Code Beta Program as a direct rival to Claude Code.
As geopolitical uncertainty rises and frontier AI development concentrates in the hands of just a few labs, the open-source card is allowing Chinese AI labs to claim the moral high ground.
Despite an overall performance lag behind the frontier, these Chinese models are accessible, cheap, and have crossed the threshold of being “usable” for complex end-to-end software engineering tasks. The abrupt closure of Anthropic’s Fable and Mythos models has handed these labs a massive marketing window.
And I do believe their commitment to open science is sincere, rather than just a marketing stunt. For example, most researchers at Zhipu come from strong academic backgrounds deeply involved in global research communities. Zhipu CEO Zhang Peng previously noted in an interview that receiving global recognition during the early days of the GLM series was what motivated them to keep pushing forward. They also rely heavily on the open-source community to iterate; recent versions of GLM openly adapt architectural innovations from other open models like DeepSeek and Kimi.

Grace Shao recently shared her observations in a Singapore AI conference:
Super cute. MiniMax and Z AI just told each other they’re huge fans of each other on the main stage of SuperAI. The vibes of the China AI ecosystem feels much more collegial.

To be frank, tech competition in China is notoriously brutal, and I don’t know how long this “lovey-dovey” honeymoon between rival labs will last. But for now, having multiple labs open-sourcing their research to benefit the global community—while still progressing commercially—is a clear win-win for everyone.
In a bigger picture, the divide between open and closed AI isn’t necessarily about who “cares” more about safety. Having followed Dario Amodei’s interviews and read Anthropic’s safety essays, I believe their commitment to the proprietary, closed-source model is rooted in a deeply considered effort to prevent AI from losing control. I have no intention of diminishing the gravity of that mission.
However, my perspective aligns more closely with the open-source approach: AI is not a nuclear weapon that should be locked. It is a computer science advancement that requires the collective scrutiny and ingenuity of the global community to build safeguards.
I am deeply skeptical of allowing one of the most important technologies in the human history to be concentrated within the boardrooms of just a few commercial companies. Over-concentration of power, without rigorous public regulation, is historically damaging. Rather than placing blind trust in a single commercial company, I believe in leveraging the diverse perspectives of researchers worldwide who can contribute without commercial or geopolitical agendas.
Moreover, we need a future where nations are not forced to beg for a piece of AI software from a few superpowers. Instead, we need a framework that empowers every country to develop their AI that respects their unique cultures, politics, and social fabrics—ensuring that the benefits of this technology are reclaimed by the people it is meant to serve. As Kevin Xu posted on X, open source is the only path to any AI sovereignty.

China’s really pushing the envelope and getting the US to make progress without large paywalls
This has changed substantially with this week's news reported by Reuters that China is considering limiting access to future models.
I'm thinking about this from the perspective of a 3rd country (I live in Australia) and what this means for us (and other western countries also).
https://leonardoborges.substack.com/p/47-sovereignty-is-an-inference-problem