
🙌ByteDance’s 'Gemini 3.0 Moment': Meet Seedance 2.0 and Seed2.0
ByteDance aims to become one of the world's top three AI companies—and its latest model releases bring that goal within reach.


Gemini 3.0 released in November 2025 was seen as a key milestone for Google to take the lead in the AI race. Now ByteDance is attempting to orchestrate its own Gemini 3.0 moment with a coordinated release of new models, including the video generation model Seedance 2.0 and the competitive multimodal foundation model Seed2.0.
ByteDance has long been recognized for exceptional AI applications—its chatbot app Doubao boasts over 100 million daily active users—but their AI models have lingered in the second tier. That perception may have just shifted.
The strategy mirrors Google’s Gemini 3.0 playbook: release across modalities simultaneously, demonstrate breadth of capability, and leverage existing distribution advantages to convert model strength into market dominance.
Seedance 2.0: SOTA Video Generator
Seedance 2.0 is ByteDance’s latest AI video generator, now available across ByteDance’s AI apps such as Jimeng and Doubao as well as video editing apps Jianying/CapCut. The model has gone viral over the past week and shows no signs of slowing down. Elon Musk called it “it’s happening fast,” and Jia Zhangke, the Cannes-winning Chinese director, just made a film with it.
Multimodal Input: Seedance 2.0 can process multimodal input, including text prompts, images, videos, and audio clips. All four modalities can be mixed at once to guide the output. You can add as many as 9 reference images, 3 videos, and 3 audio clips, then guide Seedance 2.0 with prompts to make generation more controllable.
Motion Stability: Seedance 2.0 shows marked improvements in physics-based motion and character consistency. The model handles complex human motion and object interactions with notably fewer artifacts than previous generation tools—a critical advancement for practical use cases.
Native Audio-Visual Synthesis: Like Sora 2, Seedance 2.0 generates synchronized audio and video in a single pass. Sound effects, dialogue, and music align natively with visuals, eliminating post-production alignment steps.
However, this also raises deepfake and portrait rights concerns, as the model can generate photorealistic celebrity likenesses with matching voice characteristics from minimal prompting.
Dynamic Cinematography: Seedance 2.0 introduces sophisticated camera movement control. Unlike earlier models constrained to static or simplistic angles, Seedance 2.0 can generate complex camera work comparable to professional cinematography. The New York Times called the model’s output “more cinematic than anything so far.”

Prompt Adherence: Seedance 2.0 demonstrates significant improvements in following user instructions precisely. The model generates content that matches prompts with substantially higher accuracy—reducing the unpredictable, lottery-like outputs that plagued earlier tools. When you specify performance details, lighting conditions, shadow direction, or camera behavior, the model respects these constraints rather than interpreting them loosely or ignoring them entirely.
Video generators have advanced rapidly over the past three years—just look at clips like “Smith eating spaghetti”—but they still haven’t unlocked the kind of commercial value that LLMs have. The latest example is Sora 2. While Sora 2 launched to significant fanfare last year, hitting #1 on the Apple App Store with over 1 million downloads, its daily active user base has now reportedly dropped below 1 million, with App Store rankings falling to the 70s-100s range.
Here’s where ByteDance’s strategic position becomes clear. ByteDance doesn’t have this problem. Seedance 2.0 can seemlessly integrate directly into:
Douyin/TikTok: The largest short-form video platform globally, where AI-generated content can be consumed within the same ecosystem it’s created. It will continue lowering the barriers to video production, ushering in an era where anyone can create. while more precisely matching each video to its ideal audience. Seedance 2.0 won’t disrupt Hollywood, but it will make short video apps even more addictive.
CapCut/Jianying: With over 800 million users globally, this video editing platform provides the practical creation environment where Seedance 2.0 can become part of standard creative workflows. For creators already paying for features like multilingual subtitles and AI script generation, AI video generation will soon become a must-have premium feature.
Inevitably, the model has drawn criticism from Hollywood studios alleging training on copyrighted content, followed by the Japanese government launching an investigation over potential Copyright Law violations. Starting February 9, ByteDance disabled real human images or videos as primary references, a significant capability restriction that suggests both regulatory pressure and the challenge of managing deepfake risks at scale. The company told South China Morning Post that “We are taking steps to strengthen current safeguards as we work to prevent the unauthorised use of intellectual property and likeness by users.”
Seed2.0: A Production-Oriented Multimodal Foundation Model
While Seedance 2.0 captured social media attention, Seed2.0 represents ByteDance’s core play for foundation model credibility.
Positioned as a “production-oriented” multimodal model, Seed2.0 emphasizes real-world complexity over benchmark optimization alone. In the Seed2.0 model card, researchers from Seed, ByteDance’s AI lab, began by analyzing how AI is actually used in China. The data revealed that unstructured information processing and analysis dominates authentic model usage, representing the largest single share. In development workflows, frontend development and bug fixing substantially dominate agentic coding requests, each far exceeding their respective category alternatives.

Therefore, the model prioritizes visual and multimodal understanding, fast and flexible inference, and reliable complex instruction execution.
Seed2.0 launches in three variants optimized for different deployment scenarios: Seed2.0 Pro for research and complex reasoning, Seed2.0 Lite for enterprise MaaS adoption, and Seed2.0 Mini for scaled applications where cost efficiency dominates.
As of February 16, 2026, Seed ranks 6th on the LMSYS Chatbot Arena Text Arena (Overall) leaderboard and 3rd on the Vision Arena leaderboard.
Multimodal Understanding: The model demonstrates strong performance across 50+ image benchmarks and 24+ video benchmarks. Seed2.0 Pro shows particular strength in visual reasoning tasks like MathVision, LogicVista, and VisuLogic, as well as spatial understanding benchmarks including DA-2K 3D spatial and RefSpatialBench.
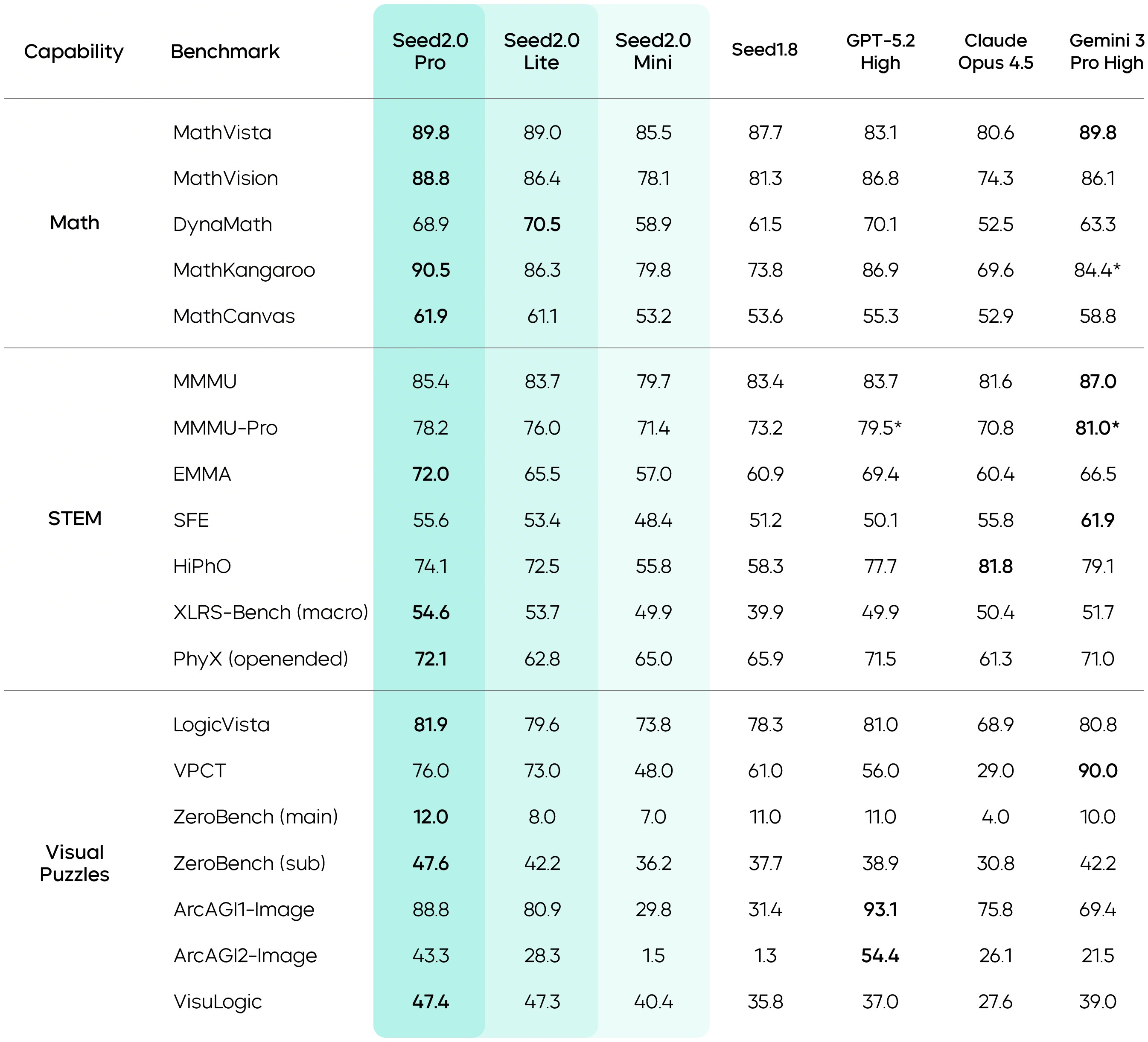
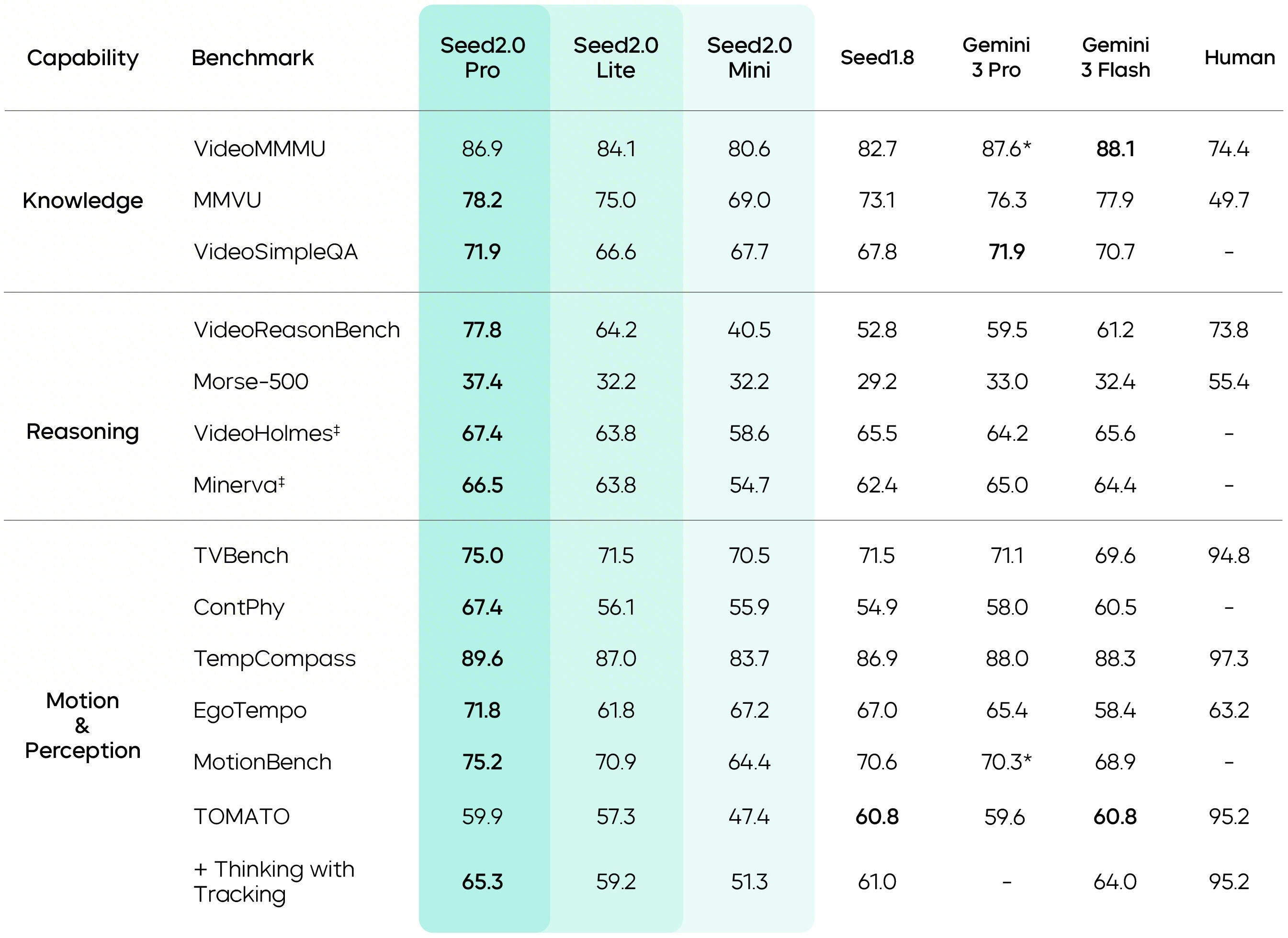
The model excels at document extraction on long-form documents (DUDE benchmark) and demonstrates exceptional motion perception capabilities—notably surpassing human baseline performance on VideoReasonBench. Long-form visual context processing represents another core strength, enabling the model to maintain coherent understanding across extended visual sequences.
Mathematical and Formal Reasoning: This is where Seed2.0 Pro shows frontier-class performance. The model achieves gold-level performance on both IMO 2025 and CMO 2025, demonstrating olympiad-level mathematical reasoning capability.
With a Codeforces Elo of 3020, Seed2.0 Pro shows strong competitive coding ability that extends beyond pure mathematics into algorithmic problem-solving. The model also delivers strong performance on AIME, HMMT, and Putnam-200 benchmarks, positioning it as competitive with Gemini 3 Pro on math and reasoning tasks across the board. Seed2.0 also pursues tackling tasks with genuine research-level complexity, such as open Erdős problems and scientific coding.

Coding Capabilities: Seed2.0 demonstrates strong coding performance across multiple evaluation dimensions. The model shows competitive results on LiveCodeBench and handles repository-level tasks effectively on NL2Repo-Bench, indicating capability beyond isolated function generation.
Debugging and refactoring scenarios, which are critical real-world workflows often underrepresented in benchmarks, represent explicit areas of focus. The model also shows particular strength in Vue.js-heavy frontend development, reflecting optimization for frameworks dominant in the Chinese market. The model card explicitly frames coding agents and multi-step task execution as design priorities, not afterthoughts, signaling ByteDance’s emphasis on practical engineering workflows over pure benchmark optimization.
Agentic Workflows: Seed2.0 emphasizes end-to-end task completion rather than single-turn interactions. Seed researchers attribute this to the nature of real-world tasks, which typically span longer time frames and involve multiple stages. Existing LLM agents struggle to independently construct efficient workflows and gain experience over extended periods, while real-world knowledge has significant domain barriers and follows a long-tail distribution. In response, the model strengthens its ability to follow complex instructions, handle long-chain tasks, and master long-tail knowledge.
The model shows strong performance as a search agent, handling complex retrieval tasks effectively. Coding agents represent a core capability, with the model demonstrating repository-level generation that goes beyond snippet completion. GUI agents, deep research workflows, and long-horizon multi-step instruction following are all explicitly supported design patterns.
Costs: While GPT-5.2 costs $1.75 per million input tokens and $14.00 per million output tokens, Seed2.0 Pro costs only $0.47/$2.37 per million input/output tokens and Seed2.0 Mini cuts costs to $0.03/$0.31 per million input/output tokens.
At 5-10x cheaper than frontier alternatives while maintaining competitive performance on many tasks, Seed2.0 targets the enterprise MaaS (Model-as-a-Service) market where cost efficiency enables entirely different use cases at scale. This aggressive pricing strategy isn't surprising—ByteDance initiated China's LLM pricing war back in April 2024, and has consistently positioned cost advantage as a core competitive moat.
However, Seed researchers also acknowledged specific gaps:
Coding performance still trails Claude on certain SWE benchmarks
Retrieval-heavy long-context tasks show headroom versus competitors
Some long-tail knowledge gaps compared to Gemini on specific QA benchmarks
Video reasoning on the hardest evaluation sets remains below human performance
Make Models Useful
The real test of AI capability isn’t found in benchmark leaderboards—it’s found in whether ordinary people can actually use it to solve their problems.
For example, my wife is a Douyin vlogger who typically spends 2-3 hours editing each video, wrestling with hour-long raw footage to add subtitles, voiceover, and special effects. She doesn’t follow AI research. She doesn’t care about benchmark scores or parameter counts. She has one question: Can AI actually save her time?
This is the audience ByteDance understands intimately. While AI researchers debate frontier capabilities and academics parse benchmark methodologies, hundreds of millions of creators on Douyin and CapCut are asking the same practical question my wife asks: Will this work for me?
When I saw Seed2.0’s model card demonstrate video editing capabilities in CapCut, I immediately shared it with her. Not because it achieved impressive scores on academic benchmarks, but because it promised to do exactly what she needs.
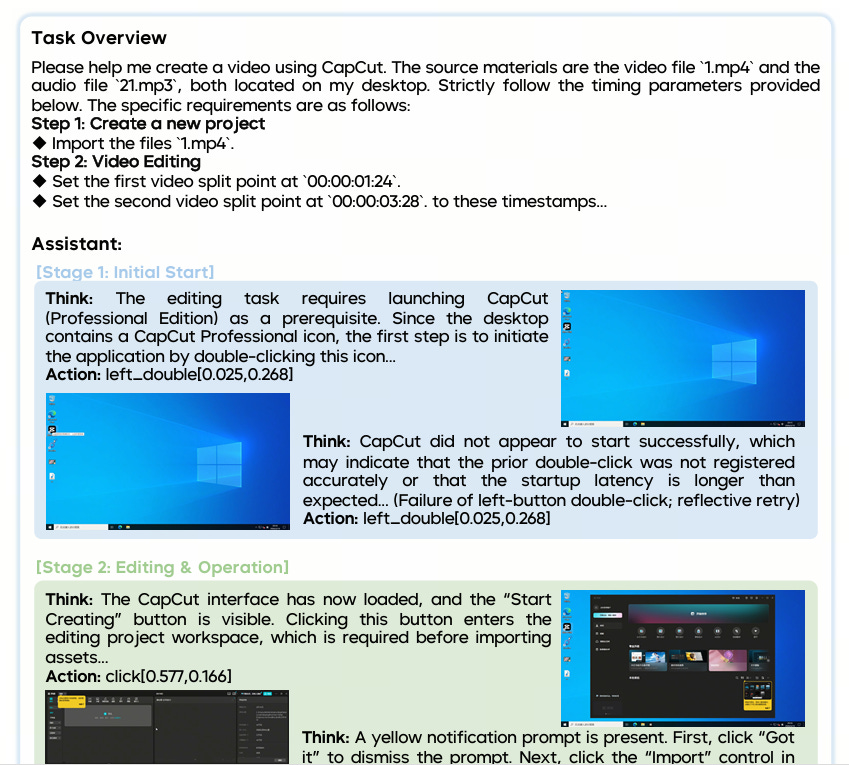
This is ByteDance’s strategic advantage. They’ve built their models not primarily for researchers to evaluate, but for real users to deploy. The company emphasizes real-world effectiveness over benchmark performance throughout Seed2.0’s documentation. Both Seedance 2.0 and Seed2.0 are engineered specifically to strengthen ByteDance’s existing applications from Douyin/TikTok to CapCut/Jianying and AI apps such as Doubao and Trae.
Unlike most Chinese tech companies rushing to open-source models for community credibility, ByteDance keeps both Seedance 2.0 and Seed2.0 proprietary, available only through their apps and cloud platforms. They’re optimizing for the number of videos actually created, the hours actually saved, the workflows actually improved.
Is this ByteDance’s Gemini 3.0 Moment? Not quite yet. Gemini 3.0, as a native multimodal model, shows exceptional capabilities across knowledge, coding, and multimodal understanding—powerful in nearly every aspect.
Seed2.0 is similar in architecture and ambition to Gemini 3.0, but more specialized. It prioritizes specific capabilities over comprehensive excellence. The Seed researchers themselves acknowledge this gap.
Seed2.0 marks the first major project since Wu Yonghui, former Google DeepMind Vice President and now head of Seed, joined ByteDance. According to Latepost, it features one trillion parameters, probably ByteDance’s largest model ever. This represents a remarkable achievement for a company that entered the LLM race late, beginning serious training only in 2023, without the robust infrastructure foundation of Google or OpenAI.
Wu is attempting to build Seed into a world-class research lab. Seedance 2.0 and Seed2.0 represent a major step in that direction—not yet matching Gemini 3.0’s comprehensive dominance, but demonstrating that ByteDance can compete at the frontier on the capabilities that matter most for its billion-user platforms.
